雨杰棋牌(3)
LogisticRegression 模型:
该模型为线性模型,形式简单,迭代快速,效果一般好,特征项有分词及 n-gram 形式的 BagOfWord 布尔特征、辅以部分规则特征和 1-gram 拼音特征,可在一定程度上捕捉句子结构及同音异形字特征,但该模型受数据集类别平衡性影响较大,需要对训练集做大量标签清洗工作。
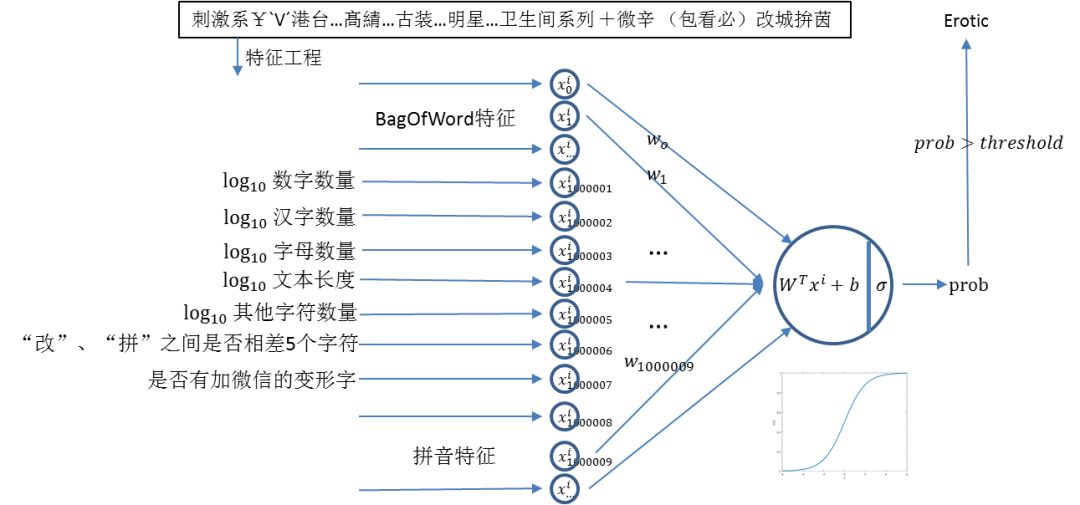
上图即为色情 LR 模型示例,其中各字符数量取对数的原因在于使所有特征取值范围相似,提高模型收敛速度。
LSTM 模型:
该模型由一个单层 LSTM 单元构成,拥有 128 维的隐层状态输出及上下文编码输出,LSTM 是一种特殊的 RNN 结构,其提出主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题,相对于普通 RNN 来说,能够在更长的序列中有着更好的表现。
Convolutional-BiLSTM 模型:
众所周知,CNN 在图像领域取得了巨大的成功,其核心之一在于卷积操作可以更好地捕捉局部特征,在文本处理中借鉴这一思想,将局部信息进一步强化,结合双向 LSTM 获取句子的编码表示,相对于单向 LSTM 来说,既包含有上文信息,又包含有下文信息,做到基于上下文语义信息判断文本是否属于垃圾。下图即为该模型结构的一个示例:

CNN 模型:
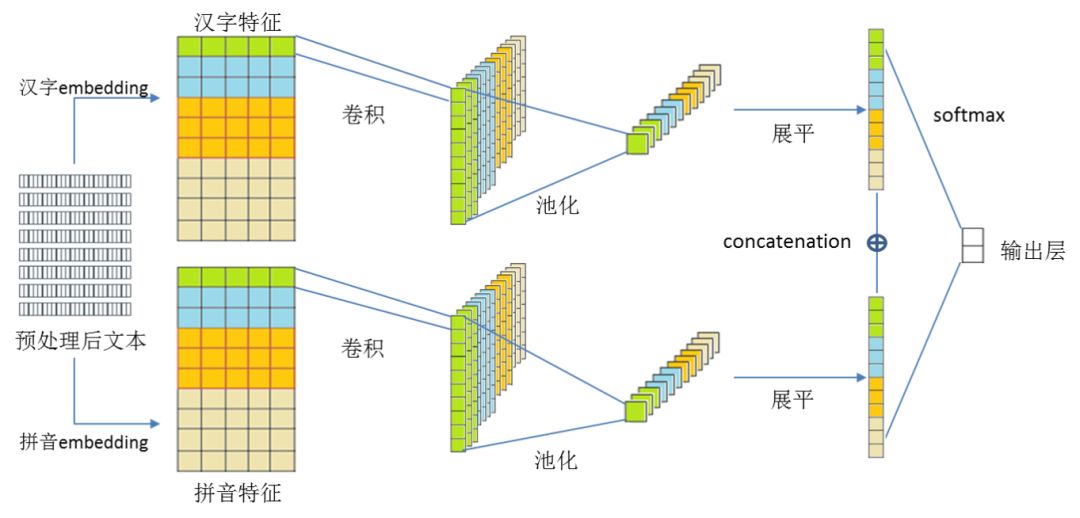
CNN 模型完全使用卷积操作来提取特征,通过不同的卷积窗口大小来获取视野和序列特征,提供强大的特征表示能力,同时,池化操作能够减少参数数量、降低噪声干扰,起到进一步特征选择的作用。
为了针对黑产经常采用的使用同音字来对汉字进行替换逃避关键词匹配或创造 OOV 条件越过模型检查的手段,如“黄色”就可以被替换为“璜色”、“煌色”、“簧色”等,我们加入了针对拼音维度的考量,拼音特征可以很好地建立替换字与原始字的对应关系,在一定程度上增加模型对替换字的识别能力,最后将汉字特征与拼音特征相结合,能够得到更强的句子表示,提高分类性能。同时,CNN 相对于 LSTM 来说,训练和预测速度更快。
Cw2vec-Attention 模型:
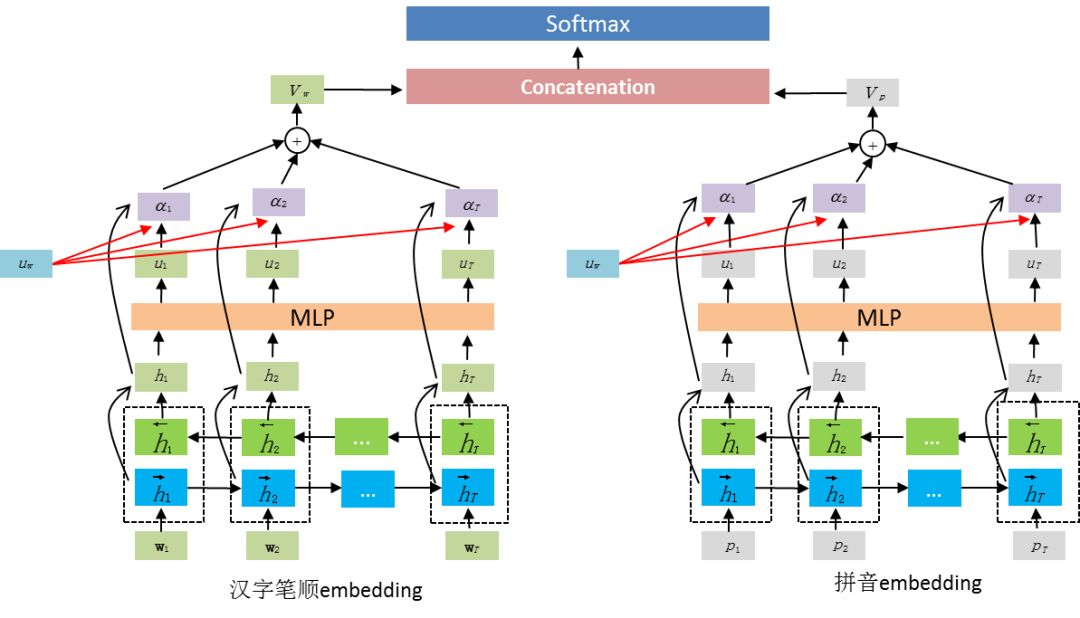
由于黑产经常对汉字进行替换来逃避检测,因此该模型关注的重点在如何找出替换字与原始字除拼音之外的联系,通过观察样本数据,我们发现,黑产除了替换为同音字之外,还会替换为同形字,如“微信”可以被替换为“徽信”、“媺信”、“徵信”、“徾信”等,而汉字笔顺特征可以较好地建立替换字与原始字的联系,因此,引入汉字部件的笔顺信息,可以在一定程度上增加模型对替换字的识别能力。同时借助 Attention 机制来获取多样化的上下文关系,增强部分特征词的作用,提高检测性能。模型架构如下图所示:
- 风控策略 —— 葵花点穴手
前面的策略,都说的是输出技能。钟馗还会控制技能,手指轻轻一点,就把敌人控制住,让他动弹不得,无法出招。
当前,钟馗所采用的风控策略只是一些简单的针对用户 ID、设备 ID 级别的规则,比如,水贴识别策略,可以判断用户一定周期内发送文本内容的相似度及频率,再决定是否用葵花点穴手将其点住,进行限制。
第四回 无尽之战
路漫漫其修远兮,吾将上下而求索
反垃圾的路,有起点,但没有终点。钟馗在成长、在壮大、在苦练学习各种武功秘籍,但作为对手的黑产们,面临巨额的诱人利益,又何尝不是呢?现在黑产们以及发展出群控、云控技术,甚至也在使用人工智能技术。这注定,不是一条一劳永逸的路,钟馗也将继续勤学苦练,完善自我。魔高一尺,那就让道,高它一丈吧。